 |
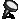 ความคิดเห็นที่ 86
ความคิดเห็นที่ 86 |

ตอบ คุณ sikap คห.83 ครับ ขอบคุณมากนะครับสำหรับความเห็น ผมเห็นด้วยบางส่วนนะครับ ขั้นตอนการพิสูจน์เริ่มต้นด้วยการฟังครับ แล้วเพราะว่าเหมือนจึงมาวิเคราะห์ถึงขั้นสัญญาณ และในขั้นนี้อยู่ระหว่างการย้อนรอย (ดังชื่อกระทู้) ครับ ว่าคนตัดต่อทำอะไรกับเสียงไปบ้าง ผมเห็นด้วยนะครับว่าการทำการทดลองทางวิทยาศาสตร์ควรทำอย่างที่คุณ sikap แนะนำก็จะดีครับ ยังไงถ้าเป็นไปได้คุณ sikap ช่วยระบุ textbook ที่พูดถึงด้วยก็จะเป็นประโยชน์มากนะครับ เพราะจะได้นำไปใช้ในการอ้างอิง
ขอตอบความเห็นต่างเป็นข้อๆ นะครับ
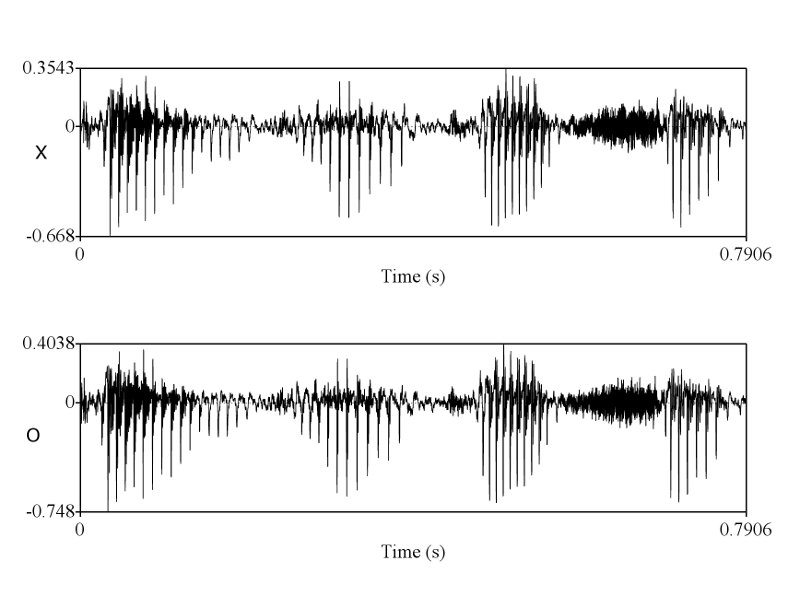
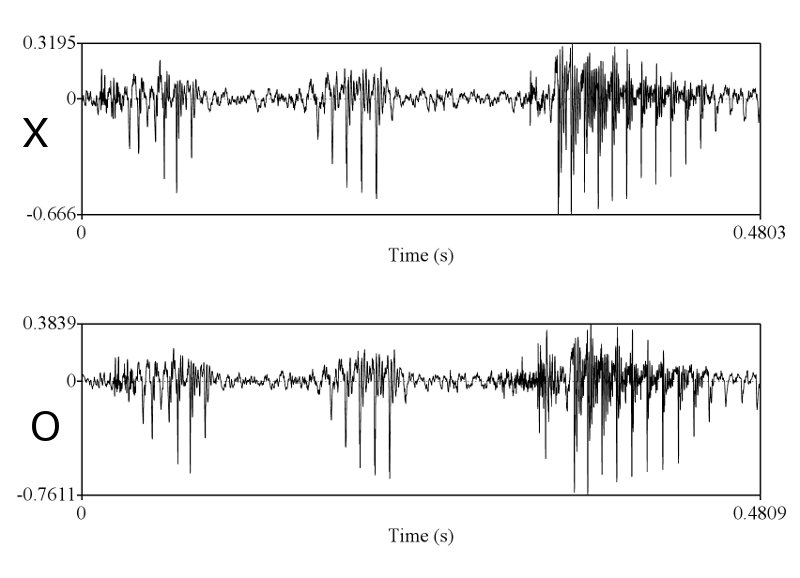
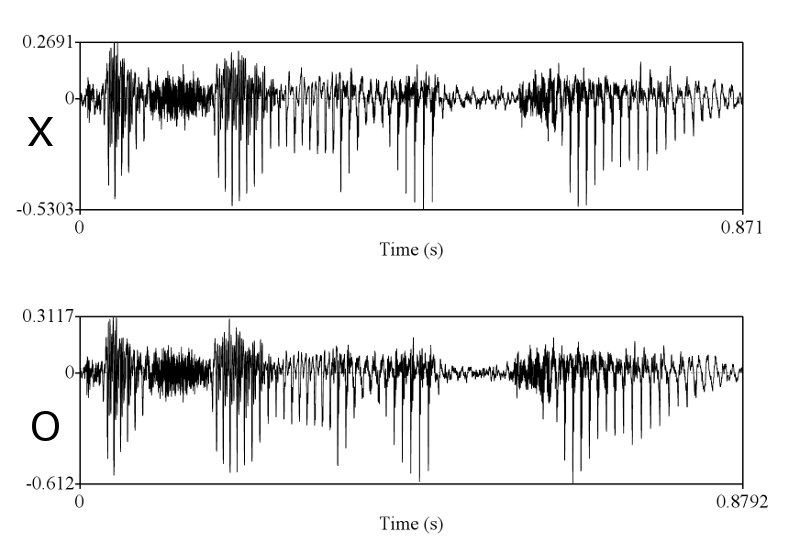
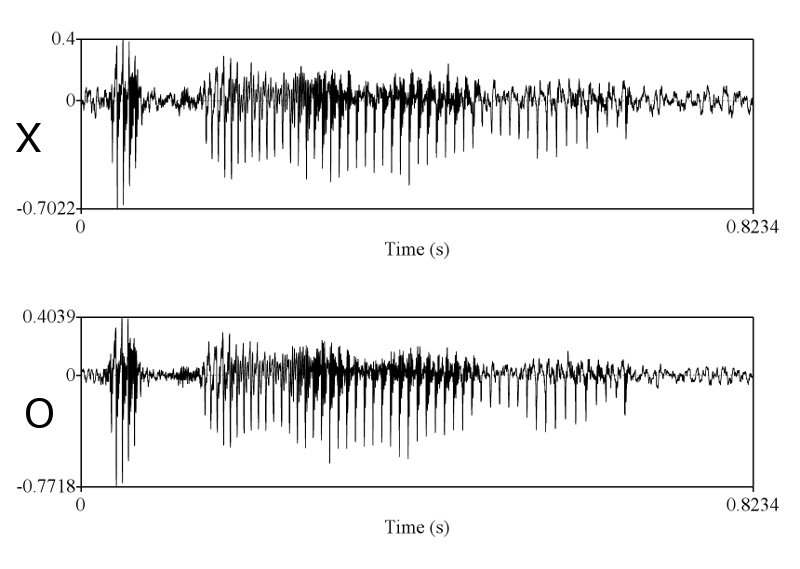
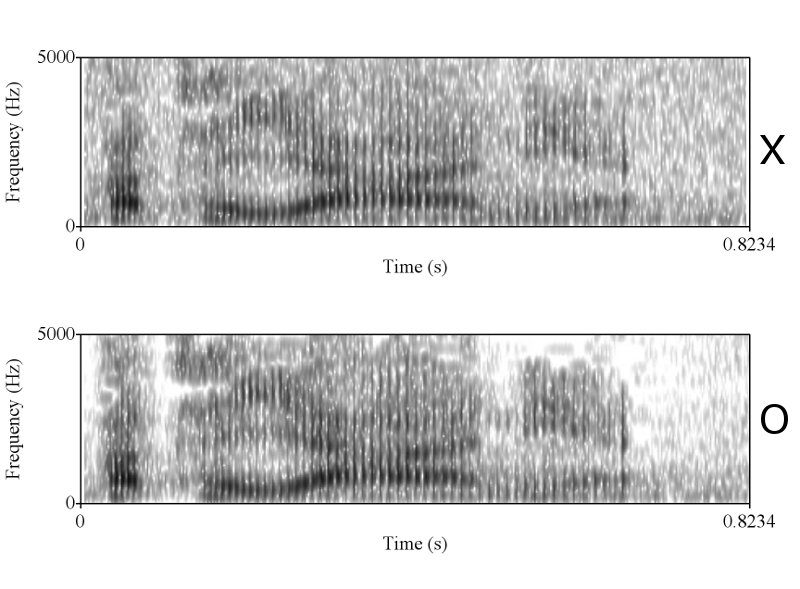
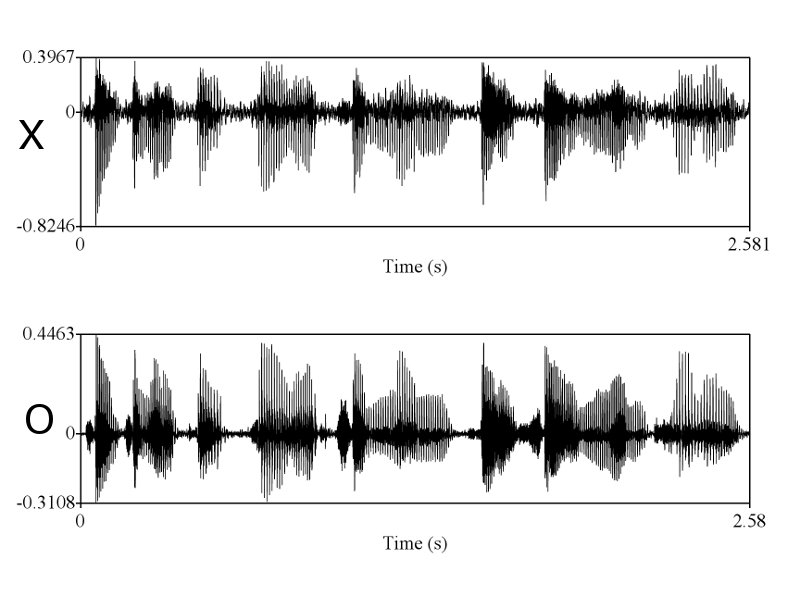
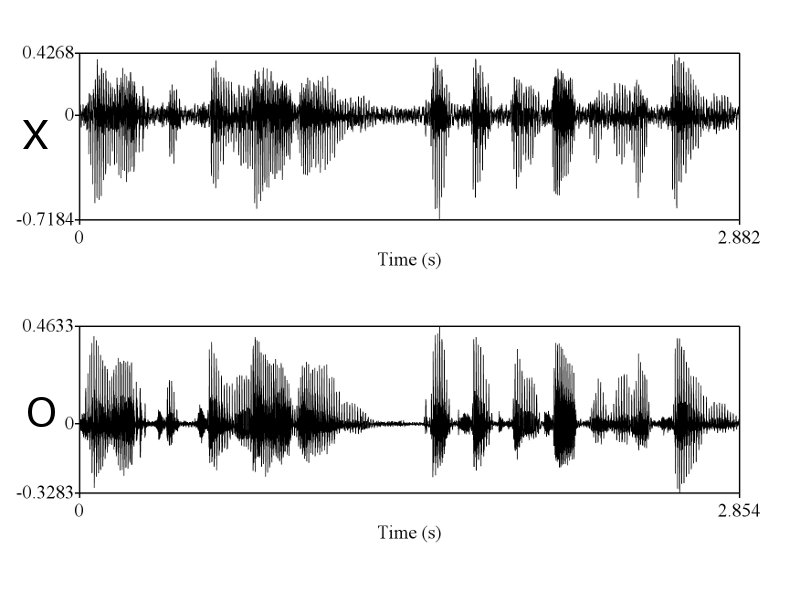
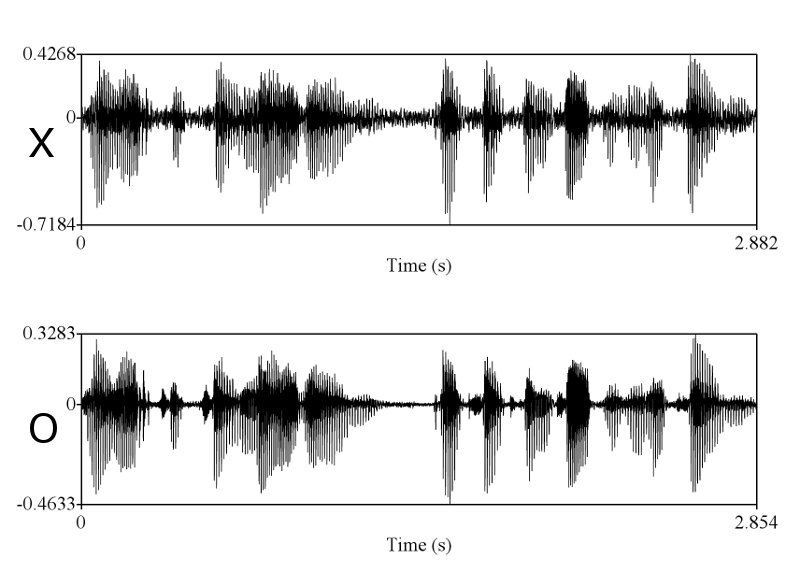
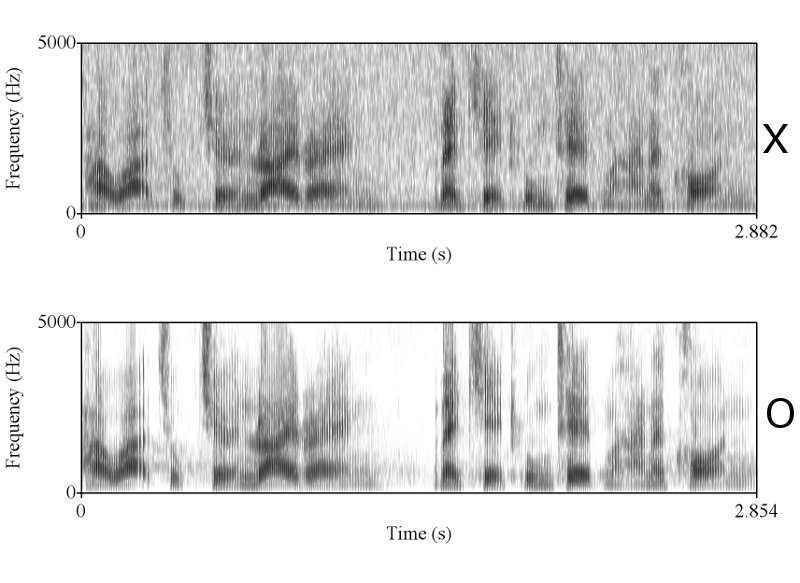
> X & O wave shape ในคห. ที่คุณนำมาเปรียบเทียบโชว์ มันก็ไม่ใช่ wave shape จากการพูดครั้งเดียวกัน คุณถ่างออกให้เห็น shape ชัดๆ
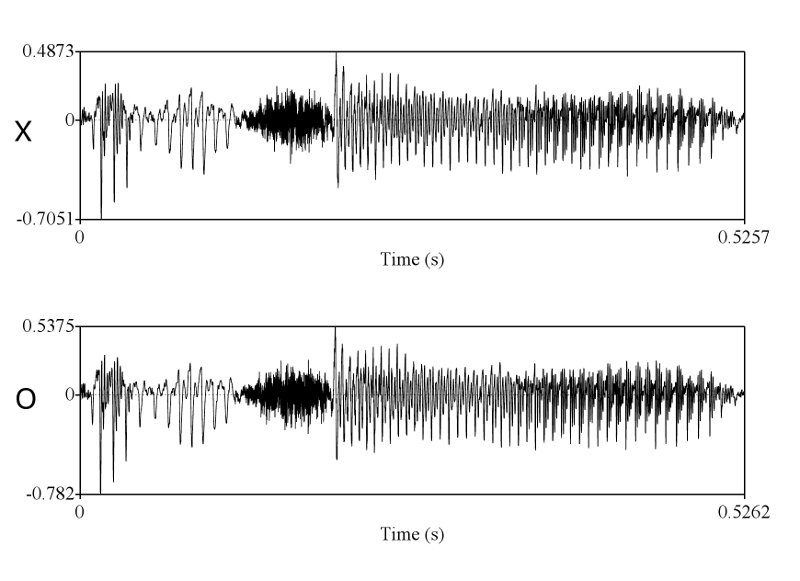
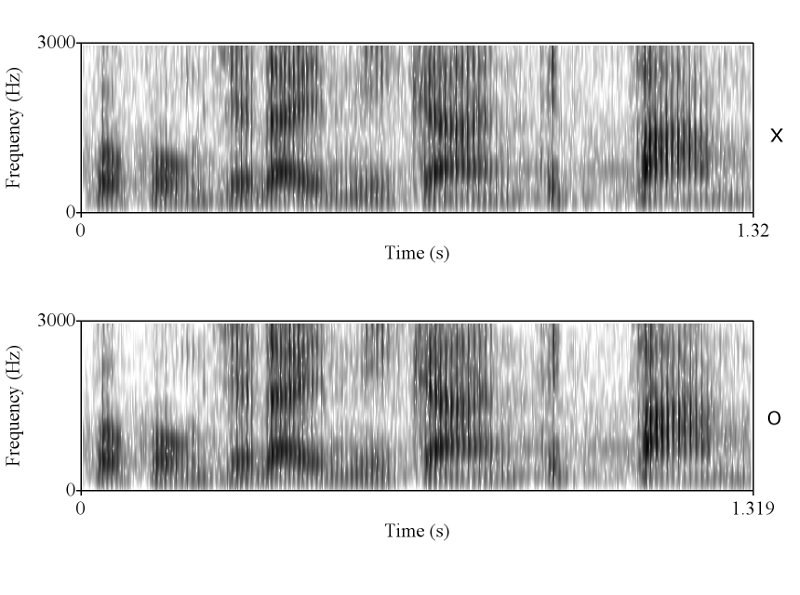
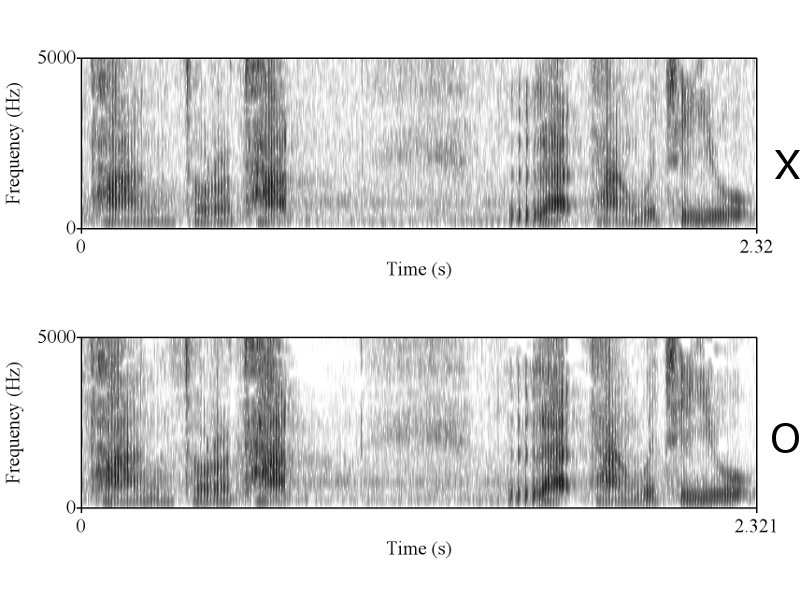
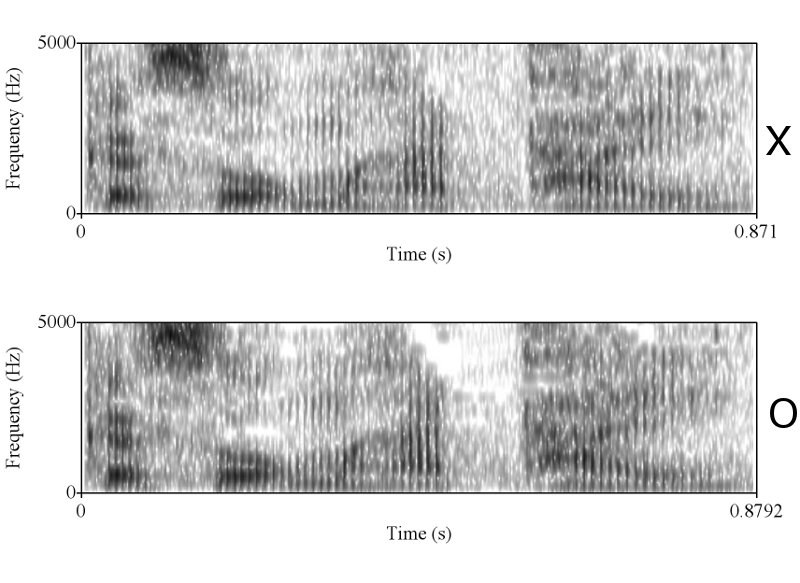
ทำไมถึงคิดว่าไม่ใช่ละครับ ในเมื่อทั้งช่วงเวลาของการออกเสียงก็เท่ากัน ลักษณะ envelop ของเสียงก็เหมือนกัน การเปลี่ยนแปลงในการออกเสียงแบบ voice และ unvoice ก็เหมือนกัน มีโครงสร้าง formant track ที่เหมือนกัน ผมว่าถ้าเป็นไปได้คุณ sikap น่าจะโชว์ให้พวกเราเห็นได้นะครับ ว่าการที่เราพูดคนละครั้งกันแล้วให้ได้ทุกอย่างซึ่งอย่างที่คุณ sikap บอกว่าเสียงมันมี variation สูงมาก ได้เท่ากันนั้นทำได้อย่างไร
>วัดยอดคลื่น ความห่างของแต่ละยอดคลื่น ซ้อนทับกันดูว่าเท่ากันไหม ?
จากสายตาบอกได้ว่าไม่เท่า
เท่าครับ ผมลองเอา pitch contour ซึ่งก็คือสิ่งที่คุณ sikap พูดถึง (ระยะระหว่างยอดคลื่น) มา plot ซ้อนทำกันแล้ว ถ้าอยากเห็นบอกนะครับ ผมจะเอามาโชว์ให้ดู
>รูปร่าง มันเหมือน ก็เพราะมันเป็นถ้อยความเดียวกัน แต่ถ้าเราต้องการรู้ว่ามันเป็นการพูดในครั้งเดียวกันหรือพูดคนละครั้ง เราต้อง วัด shape ดูจะรู้ว่าไม่ได้พูดจากครั้งเดียวกัน
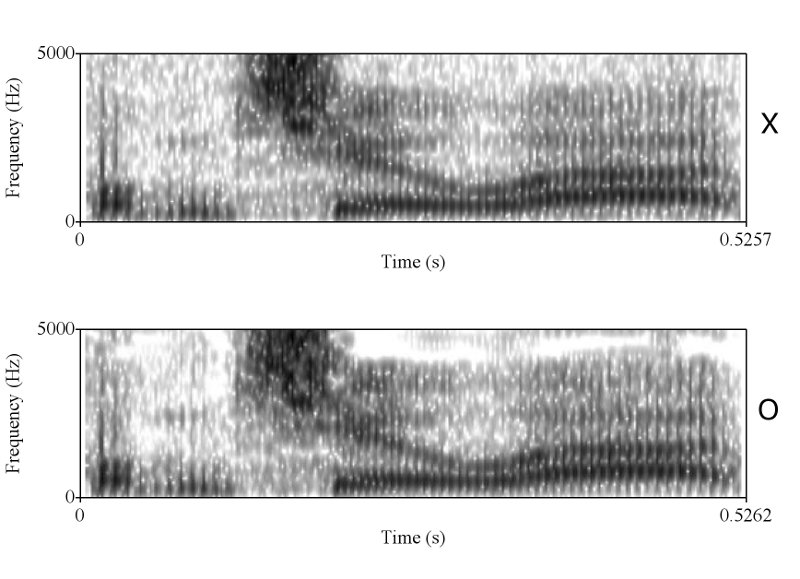
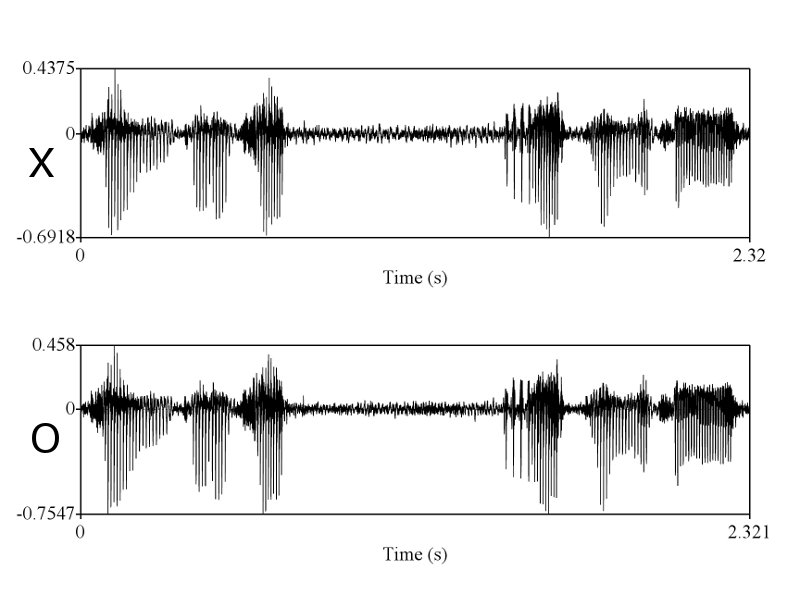
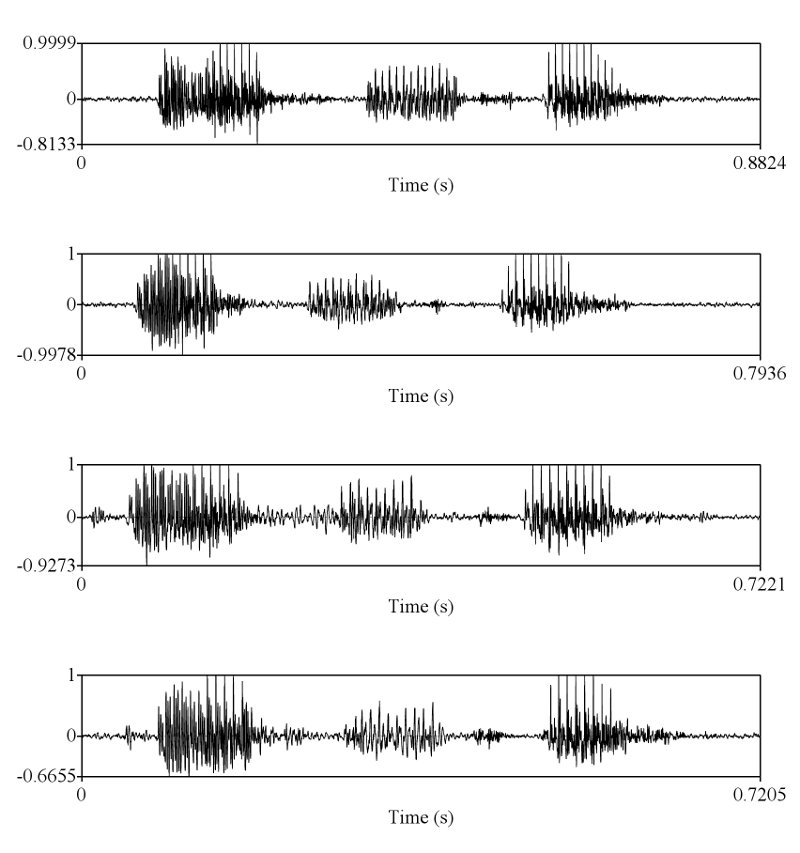
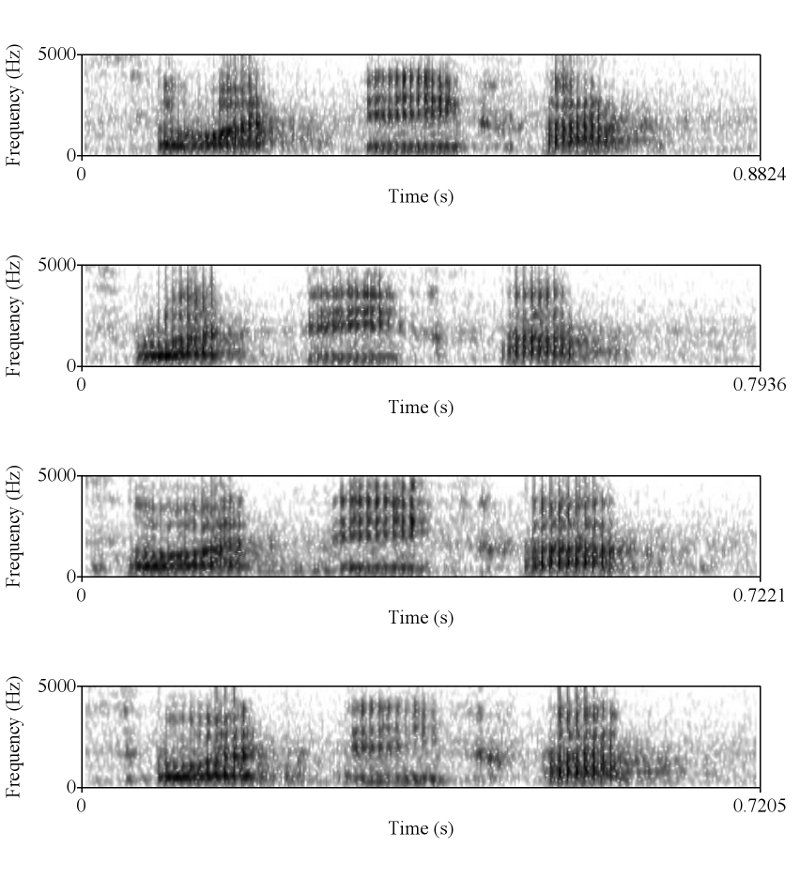
ถูกแต่ถูกไม่หมดครับ เราต้องวัด shape ครับ แต่พอวัดดูแล้วเราถึงสรุปได้ไงครับ ว่ามันเท่ากัน และเป็นการพูดครั้งเดียวกัน ถ้าคุณ sikap มีหลักฐานว่าการพูดคนละครั้ง ในประโยคที่มีความยาด 0-5 วินาที สามารถสร้าง waveform และ spectrogram ได้เหมือนกันขนาดนี้ได้ ผมถึงจะยอมเชื่อคุณ sikap ครับ อ้อ ต้องหลายๆ ประโยคอย่างที่ผมเอามาแสดงด้วยนะครับ
>การพูด ต่างกรรมต่างวาระของคนๆเดียวกัน แม้จะพูดถ้อยความเดียวกัน แต่ frequency & amplitude specification ที่ออกมาจะไม่เท่ากันหรอก มันขึ้นกับความถี่หรือการขึ้นสูง-ลงต่ำของเสียง, ความดัง, ความเร็ว(tempo), น้ำเสียง(register), ความต่อเนื่องการพูด ณ ขณะนั้น
ถูกต้องครับ ดังนั้นการที่เสียงจาก 2 ที่มีความเหมือนกันในเชิงของ formant track, รูปร่างของสัญญาณซึ่งแสดงถึงความดัง, ความเร็ว (speaking rate ครับ, tempo เป็นศัพท์ทางดนตรีครับ มักไม่ค่อยใช้กันเสียงมนุษย์), น้ำเสียง (ตรงนี้ทางวิชาการใช้คำว่า voice quality นะครับ), ลักษณะการพูดต่อเนื่อง และเหมือนกันเช่นนี้หลายๆ จุดจึงสรุปได้เพียงอย่างเดียวว่ามันมาจากแหล่งเดียวกันครับ
แก้ไขเมื่อ 07 ก.ย. 52 00:35:01
| จากคุณ |
:
phonetics 
|
| เขียนเมื่อ |
:
6 ก.ย. 52 23:24:01
|
|
|
|
|






 จริงๆ speech science เป็นศาสตร์ที่เค้าเรียกว่า สหกิจศึกษา (interdisciplinary) นะครับ เพราะต้องใช้ความรู้หลายด้าน ทั้งทางด้าน physics ด้านการประมวลผลสัญญาณ ด้าน phonetics ด้าน linguistics ด้าน human physiology ที่ ม ที่ผมเคยไปทำวิจัย (UCL) เลยมีการที่เค้ายุบรวมเอาผู้เชี่ยวชาญมาตั้งเป็น cluster วิจัยด้าน speech โดยเฉพาะครับ
จริงๆ speech science เป็นศาสตร์ที่เค้าเรียกว่า สหกิจศึกษา (interdisciplinary) นะครับ เพราะต้องใช้ความรู้หลายด้าน ทั้งทางด้าน physics ด้านการประมวลผลสัญญาณ ด้าน phonetics ด้าน linguistics ด้าน human physiology ที่ ม ที่ผมเคยไปทำวิจัย (UCL) เลยมีการที่เค้ายุบรวมเอาผู้เชี่ยวชาญมาตั้งเป็น cluster วิจัยด้าน speech โดยเฉพาะครับ



 ... เข้ามาดู
... เข้ามาดู
